This blog is written by guest blogger Ben Rushton, Application Specialist/Territory Manager at Promega Australia.
When you’re monitoring marine biodiversity at scale, every drop of seawater tells a story. At Minderoo OceanOmics Centre at the University of Western Australia, scientists are uncovering that story through environmental DNA (eDNA)—and automation is helping them listen more clearly.
Laura Missen, a Scientific Officer at OceanOmics Centre, shares how automating their DNA extraction workflow with the Maxwell® RSC 48 system has transformed how they gather and interpret data from marine ecosystems.
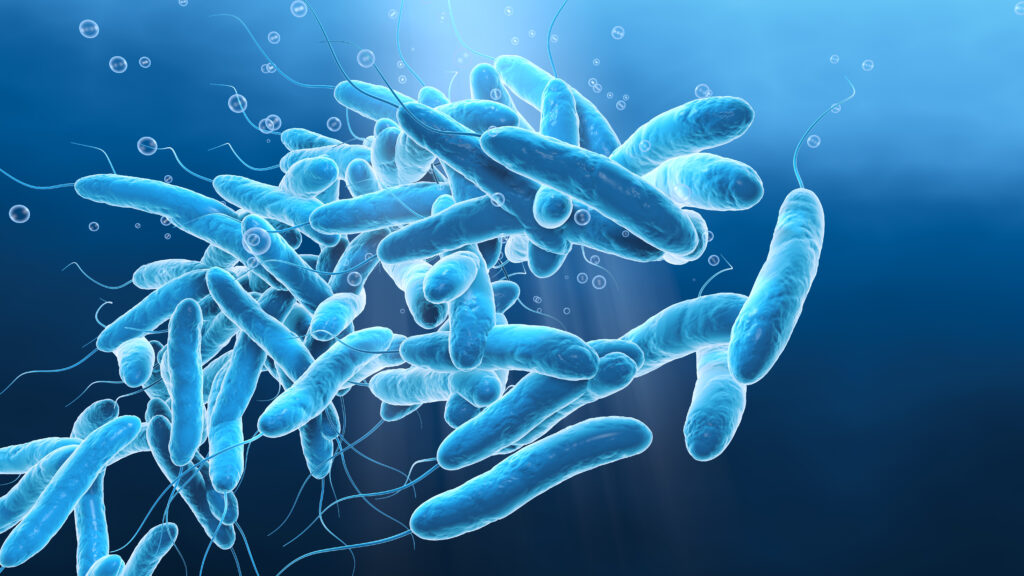
Water plays a vital role in countless aspects of daily life—drinking, cooling, recreation and more. However, the same systems that deliver these benefits can also harbor Legionella, a waterborne bacteria responsible for Legionnaires’ disease, a severe form of pneumonia (1). Legionella thrives in stagnant aquatic environments, many of which are human-made and common in modern infrastructure, like in cooling towers, hot tubs and complex building water systems. In this blog, we explore the risks posed by Legionella, the limitations of traditional detection methods and how advanced tools at Promega are transforming water safety monitoring.
Almost three-quarters of the major crop plants across the globe depend on some kind of pollinator activity, and over one-third of the worldwide crop production is affected by bees, birds, bats, and other pollinators such as beetles, moths and butterflies (1). The economic impact of pollinators is tremendous: Between $235–577 billion dollars of global annual food production relies on the activity of pollinators (2). Nearly 200,000 species of animals act as pollinators, including some 20,000 species of bees (1). Some of the relationships between pollinators and their target plants are highly specific, like that between fig plants and the wasps that pollinate them. Female fig wasps pollinate the flowers of fig plants while laying their eggs in the flower. The hatched wasp larvae feed on some, but not all, of the seeds produced by fertilization. Most of the 700 fig plants known are each pollinated by only one or a few specific wasp species (3). These complex relationships are one reason pollinator diversity is critical.
Measuring the Success of Conservation Legislation
A bee pollinates the lavender flowers.
We are now beginning to recognize how critical pollinator diversity is to our own survival, and many governments, from the local level to the national level are enacting policies and legislation to help protect endangered or threatened pollinator species. However, ecosystems and biodiversity are complex subjects that make measuring and attributing meaningful progress on conservation difficult. Not only are there multiple variables in every instance, but determining the baseline starting point before the legislation is difficult. However, there are dramatic examples of success in saving species through legislative and regulatory action. The recovery of the bald eagle and other raptor populations in the United States after banning the use of DDT is one such example (4).
Today’s blog is written by guest blogger, Sameer Moorji, Director, Applied Markets.
People’s diets are frequently influenced by a wide range of variables; with environment, socioeconomic status, religion, and culture being a few of the key influencers. The Muslim community serves as one illustration of how culture and religion can hold influence over people’s eating habits.
Muslims, who adhere to Islamic teachings derived from the Qur’an, frequently base dietary choices on a food’s halal status, whether it is permissible to consume, or haram status, forbidden to consume. With the population of Muslims expected to expand from 1.6 billion in 2010 to 2.2 billion by 2030, the demand for halal products is anticipated to surge (2).
By 2030, the global halal meat market is projected to reach over $300 billion dollars, with Asia-Pacific and the Middle East regions being the largest consumers and producers of halal meat products (3). Furthermore, increasing awareness and popularity of halal meat among non-Muslim consumers, as well as strengthening preference for ethical and high-quality meat, are all contributing to demand.
The WSPCP works to provide seed potato growers with healthy planting stock
The mighty potato—the Midwest’s root vegetable of choice—is susceptible to a variety of diseases that, without proper safeguards, can spell doom for your favorite side dishes. Founded in 1913 and housed in the Department of Plant Pathology at the University of Wisconsin-Madison, the Wisconsin Seed Potato Certification Program (WSPCP) helps Wisconsin seed potato growers maintain healthy, profitable potato crops year-to-year through routine field inspections, a post-harvest grow-out and laboratory testing.
While WSPCP conducts visual inspections for various seed potato pathogens, their diagnostic laboratory testing is primarily focused on viruses such as Potato virus Y (PVY), which can cause yield reduction and tuber defects, along with select bacteria such as Dickeya and Pectobacterium species that cause symptoms like wilting, stem rot and tuber decay.
Foodborne disease affects almost 1 in 10 people around the world annually, and continuously presents a serious public health issue (9).
Food Contamination is common and can be seen in a variety of forms and food products.
More than 200 diseases have evolved from consuming food contaminated by bacteria, viruses, parasites, and chemical substances, resulting in extensive increases in global disease and mortality rates (9). With this, foodborne pathogens cause a major strain on health-care systems; as these diseases induce a variety of different illnesses characterized by a multitude of symptoms including gastrointestinal, neurological, gynecological, and immunological (9,2).
But why is food contamination increasing?
New challenges, in addition to established food contamination hazards, only serve to compound and increase food contamination risks. Food is vulnerable to contamination at any point between farm and table—during production, processing, delivery, or preparation. Here are a few possible causes of contamination at each point in the chain (2):
Production: Infected animal biproducts, acquired toxins from predation and consumption of other sick animals, or pollutants of water, soil, and/or air.
Processing: Contaminated water for cleaning or ice. Germs on animals or on the production line.
Delivery: Bacterial growth due to uncontrolled temperatures or unclean mode of transport.
Preparation: Raw food contamination, cross-contamination, unclean work environments, or sick people near food.
Further emerging challenges include, more complex food movement, a consequence of changes in production and supply of imported food and international trade. This generates more contamination opportunities and transports infected products to other countries and consumers. Conjointly, changes in consumer preferences, and emerging bacteria, toxins, and antimicrobial resistance evolve, and are constantly changing the game for food contamination (1,9).
Hence, versatile tests that can identify foodborne illnesses in a rapid, versatile, and reliable way, are top priority.
In the fifty years since the first reported transformation of recombinant plasmids into bacteria (1), plasmid cloning has become one of the pillars of synthetic biology research and manufacturing biopharmaceuticals.
But purifying plasmids is no small feat. It can often take hours of hands-on time to go from culture to eluate with low-throughput and time-sensitive manual methods. Automating plasmid purification is the way to go, whether you’re isolating a single plasmid from a large volume culture or creating a library of thousands of different constructs.
We recently posted a blog about Proteinase K, a serine protease that exhibits broad cleavage activity produced by the fungus Tritirachium album Limber. It cleaves peptide bonds adjacent to the carboxylic group of aliphatic and aromatic amino acids and is useful for general digestion of protein in biological samples. In that previous blog we focused on its use to remove RNase and DNase activities. However, the stability of Proteinase K in urea and SDS and its ability to digest native proteins make it useful for a variety of applications. Here we provide a brief list of peer-reviewed citations that demonstrate the use of proteinase K in DNA and RNA purification, protein digestion in FFPE tissue samples, chromatin precipitation assays, and proteinase K protection assays:
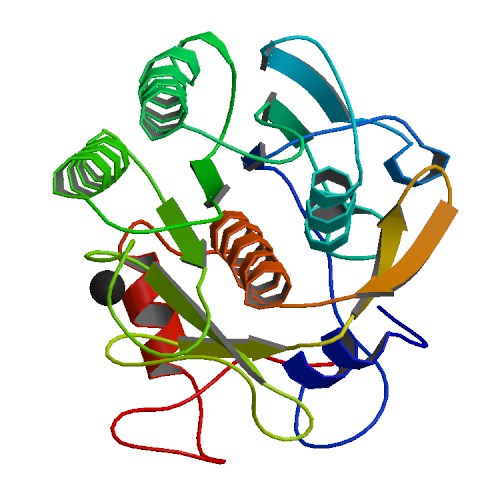
Proteinase K Ribbon Structure ImageSource=RCSB PDB; StructureID=4b5l; DOI=http://dx.doi.org/10.2210/pdb4b5l/pdb;
If you enter any molecular lab asking to borrow some Proteinase K, lab members are likely to answer: “I know we have it. Let me see where it is”. Sometimes the enzyme will be found to have expired. The lab may also have struggled with power outages or freezer malfunctions in the past. But the lab still decides to keep the enzyme. One may rightly ask – why do labs hang on to Proteinase K even when it has been stored under sub-standard conditions?
Aberrant methylation events have significant impacts in terms of incidence of cancer and development disregulation. Researchers studying DNA methylation are often working with DNA from “difficult” tissues such as formalin-fixed, paraffin embedded tissues, which characteristically yield DNA that is more fragmented than that purified from fresh tissue. Traditional methods for bisulfite conversion involve a long protocol, harsh chemicals, and generally yield highly fragmented DNA. The DNA fragmentation may significantly impact the utility of the converted DNA in downstream applications such as bisulfite-specific PCR or bisulfite sequencing.
An ideal bisulfite conversion system enables complete conversion of a DNA sample in a short period of time, provides high yield of DNA, minimally fragments the DNA, works on a wide range of input DNA amounts (from a wide variety of sample types), and, while we’re at it, is easy to use and to store. Whew! That’s quite the list.
XWe use cookies and similar technologies to make our website work, run analytics, improve our website, and show you personalized content and advertising. Some of these cookies are essential for our website to work. For others, we won’t set them unless you accept them. To learn more about our approach to Privacy we invite you to Read More
By clicking “Accept All”, you consent to the use of ALL the cookies. However you may visit Cookie Settings to provide a controlled consent.
We use cookies and similar technologies to make our website work, run analytics, improve our website, and show you personalized content and advertising. Some of these cookies are essential for our website to work. For others, we won’t set them unless you accept them. To find out more about cookies and how to manage cookies, read our Cookie Policy.
If you are located in the EEA, the United Kingdom, or Switzerland, you can change your settings at any time by clicking Manage Cookie Consent in the footer of our website.
Necessary cookies are absolutely essential for the website to function properly. These cookies ensure basic functionalities and security features of the website, anonymously.
Cookie
Duration
Description
cookielawinfo-checbox-analytics
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics".
cookielawinfo-checbox-functional
11 months
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional".
cookielawinfo-checbox-others
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other.
cookielawinfo-checkbox-advertisement
1 year
The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Advertisement".
cookielawinfo-checkbox-necessary
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary".
cookielawinfo-checkbox-performance
11 months
This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance".
gdpr_status
6 months 2 days
This cookie is set by the provider Media.net. This cookie is used to check the status whether the user has accepted the cookie consent box. It also helps in not showing the cookie consent box upon re-entry to the website.
lang
This cookie is used to store the language preferences of a user to serve up content in that stored language the next time user visit the website.
viewed_cookie_policy
11 months
The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data.
Analytical cookies are used to understand how visitors interact with the website. These cookies help provide information on metrics the number of visitors, bounce rate, traffic source, etc.
Cookie
Duration
Description
SC_ANALYTICS_GLOBAL_COOKIE
10 years
This cookie is associated with Sitecore content and personalization. This cookie is used to identify the repeat visit from a single user. Sitecore will send a persistent session cookie to the web client.
vuid
2 years
This domain of this cookie is owned by Vimeo. This cookie is used by vimeo to collect tracking information. It sets a unique ID to embed videos to the website.
WMF-Last-Access
1 month 18 hours 24 minutes
This cookie is used to calculate unique devices accessing the website.
_ga
2 years
This cookie is installed by Google Analytics. The cookie is used to calculate visitor, session, campaign data and keep track of site usage for the site's analytics report. The cookies store information anonymously and assign a randomly generated number to identify unique visitors.
_gid
1 day
This cookie is installed by Google Analytics. The cookie is used to store information of how visitors use a website and helps in creating an analytics report of how the website is doing. The data collected including the number visitors, the source where they have come from, and the pages visted in an anonymous form.
Advertisement cookies are used to provide visitors with relevant ads and marketing campaigns. These cookies track visitors across websites and collect information to provide customized ads.
Cookie
Duration
Description
IDE
1 year 24 days
Used by Google DoubleClick and stores information about how the user uses the website and any other advertisement before visiting the website. This is used to present users with ads that are relevant to them according to the user profile.
test_cookie
15 minutes
This cookie is set by doubleclick.net. The purpose of the cookie is to determine if the user's browser supports cookies.
VISITOR_INFO1_LIVE
5 months 27 days
This cookie is set by Youtube. Used to track the information of the embedded YouTube videos on a website.
Performance cookies are used to understand and analyze the key performance indexes of the website which helps in delivering a better user experience for the visitors.
Cookie
Duration
Description
YSC
session
This cookies is set by Youtube and is used to track the views of embedded videos.
_gat_UA-62336821-1
1 minute
This is a pattern type cookie set by Google Analytics, where the pattern element on the name contains the unique identity number of the account or website it relates to. It appears to be a variation of the _gat cookie which is used to limit the amount of data recorded by Google on high traffic volume websites.